

I know I violated one of my old web rules ("Once you put a web page online at a specific Url, never break that Url."), but I removed a lot of content when I re-built this site's back-end recently. Not that this site ever had a huge amount of content. But I broke a number of links to web pages that I suspected people were looking for, even if the requests came only once in a blue moon.
I now have a system in place for fixing these broken links. It's not ideal, and is only reactive, not proactive, but eventually users will no longer see errors on this site, even if the content has moved or is missing altogether. Here is how it's done:
- When the web server gets a request for an Url it can't find, it sends the user to a special custom Url.
- This special custom Url logs the request, including
- the missing Url, itself,
- if available, the page that linked to this missing Url,
- the IP address from which the request came,
- the User Agent that made the request.
- From time to time, I review this log and I either
- restore the missing Url
- if the content exists in a new location, seamlessly redirect the user to the new Url, or
- display an error message that says the content is no longer available
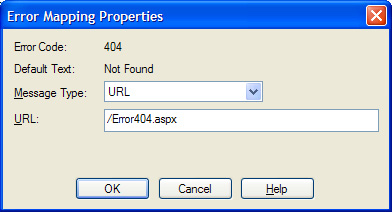
The first step is easy and is something every webmaster should do: create a custom error-handler. On Microsoft's Internet Information Server (IIS), there are two ways to do it. If you have access to IIS Manager, open your Web Site Properties, click the Custom Errors tab, click "404" under the HTTP Error column, and click "Edit Properties." In this example, the Message Type is changed from "File" to "URL" and the Url of a custom ASP.Net page is entered.
A second way is to set up custom error handling in your web.config file.
Which method you are able to use depends on your web hosting service and the server software they are running.
Once a 404 error has been referred to it, this custom ASP.Net page logs the request by accessing the System.Web.HttpContext.Current.Request object. The Url requested is extracted from the Request.ServerVariables["QUERY_STRING"]object. The referring web page is in the Request.UrlReferrer object. The IP address of the requester is in the Request.ServerVariables["REMOTE_HOST"] object. And the User Agent is in the Request.ServerVariables["HTTP_USER_AGENT"] object. This information is saved to a text file for parsing later.
If this missing Url actually exists in a different location on the site, the user is redirected with a call to System.Web.HttpContext.Current.Response.Redirect. The server knows where to send you because it finds the missing Url in an Xml file that I painstakingly maintain. Here is an example:
/default.asp was the old www.DavesWeb.com default home page, and /default.aspx is the new one. Request http://www.DavesWeb.com/default.asp, and you'll be sent automatically to http://www.DavesWeb.com/default.aspx. You shouldn't even notice. In fact, you'll still see http://www.DavesWeb.com/default.asp in your browser's Url field.
This applies to images, as well as web pages. Several years ago I posted a message on RangerPowerSports.com, a site about Ford Ranger pick-ups. I had figured out how to do a difficult procedure on my truck and posted a message on how to do it. I included pictures that showed where to find several crucial but hard-to-find bolts. I put the images on DavesWeb.com. When I re-built my site, I broke the links to those images. But using the process outlined above, I could see where users were still looking at that old article, but not seeing the images (of course rendering the article virtually worthless). Now, the pictures are back and I hope that some poor old Ranger shadetree mechanic is finding the article helpful. From my logs, I can see that people are, indeed, still viewing this page.
I'm glad I can still help.